

[ad_1]

Anthropic / Benj Edwards
On Thursday, Anthropic introduced Claude 3.5 Sonnet, its newest AI language mannequin and the primary in a brand new sequence of “3.5” fashions that construct upon Claude 3, launched in March. Claude 3.5 can compose textual content, analyze information, and write code. It includes a 200,000 token context window and is obtainable now on the Claude web site and thru an API. Anthropic additionally launched Artifacts, a brand new characteristic within the Claude interface that exhibits associated work paperwork in a devoted window.
Up to now, individuals exterior of Anthropic appear impressed. “This mannequin is absolutely, actually good,” wrote impartial AI researcher Simon Willison on X. “I believe that is the brand new finest total mannequin (and each quicker and half the value of Opus, much like the GPT-4 Turbo to GPT-4o soar).”
As we have written earlier than, benchmarks for giant language fashions (LLMs) are troublesome as a result of they are often cherry-picked and sometimes don’t seize the texture and nuance of utilizing a machine to generate outputs on virtually any conceivable subject. However based on Anthropic, Claude 3.5 Sonnet matches or outperforms competitor fashions like GPT-4o and Gemini 1.5 Professional on sure benchmarks like MMLU (undergraduate degree data), GSM8K (grade college math), and HumanEval (coding).
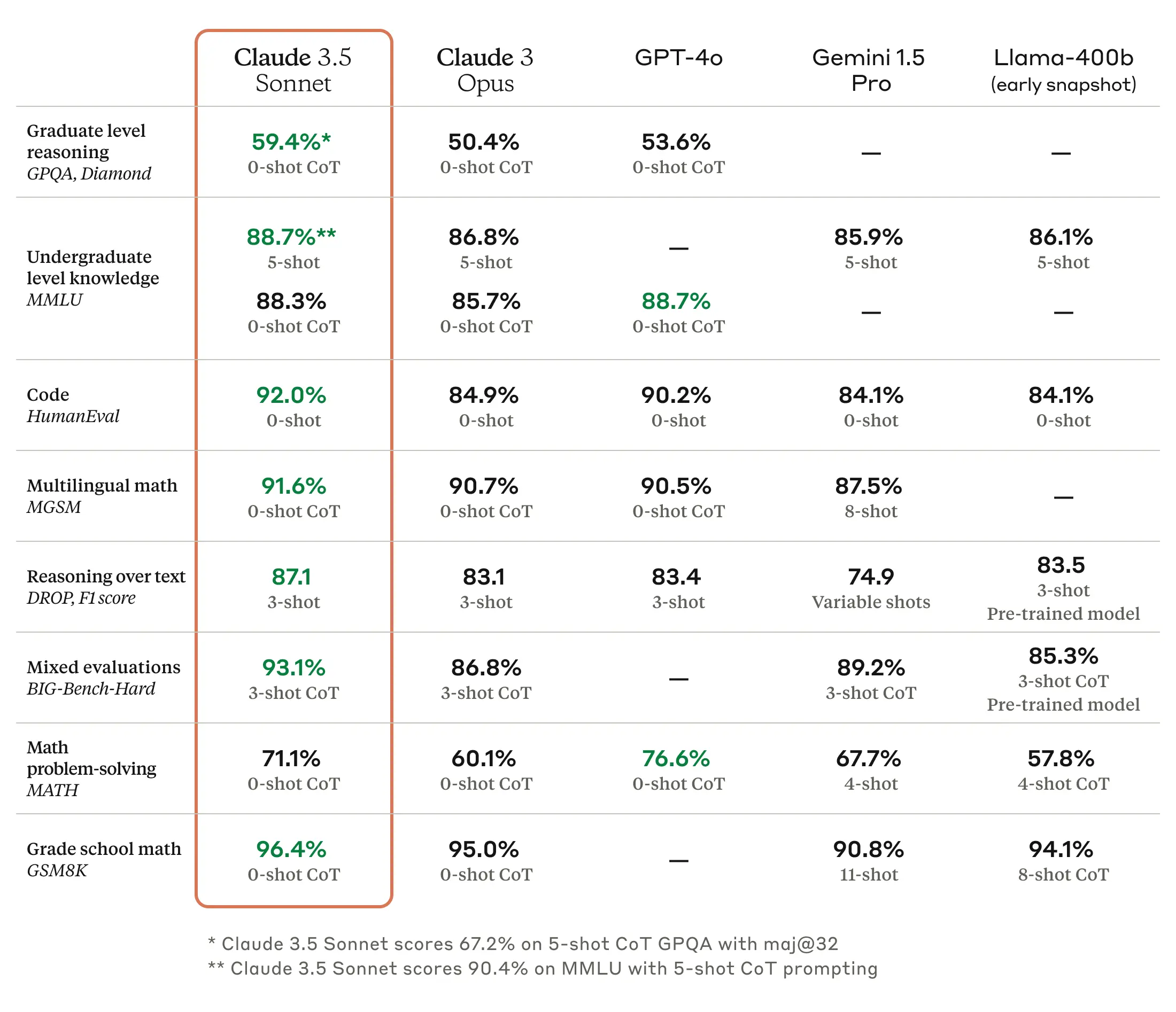
If all that makes your eyes glaze over, that is OK; it is significant to researchers however principally advertising to everybody else. A extra helpful efficiency metric comes from what we would name “vibemarks” (coined right here first!) that are subjective, non-rigorous mixture emotions measured by aggressive utilization on websites like LMSYS’s Chatbot Area. The Claude 3.5 Sonnet mannequin is at present beneath analysis there, and it is too quickly to say how properly it’s going to fare.
Claude 3.5 Sonnet additionally outperforms Anthropic’s previous-best mannequin (Claude 3 Opus) on benchmarks measuring “reasoning,” math expertise, common data, and coding skills. For instance, the mannequin demonstrated sturdy efficiency in an inside coding analysis, fixing 64 % of issues in comparison with 38 % for Claude 3 Opus.
Claude 3.5 Sonnet can be a multimodal AI mannequin that accepts visible enter within the type of pictures, and the brand new mannequin is reportedly wonderful at a battery of visible comprehension checks.
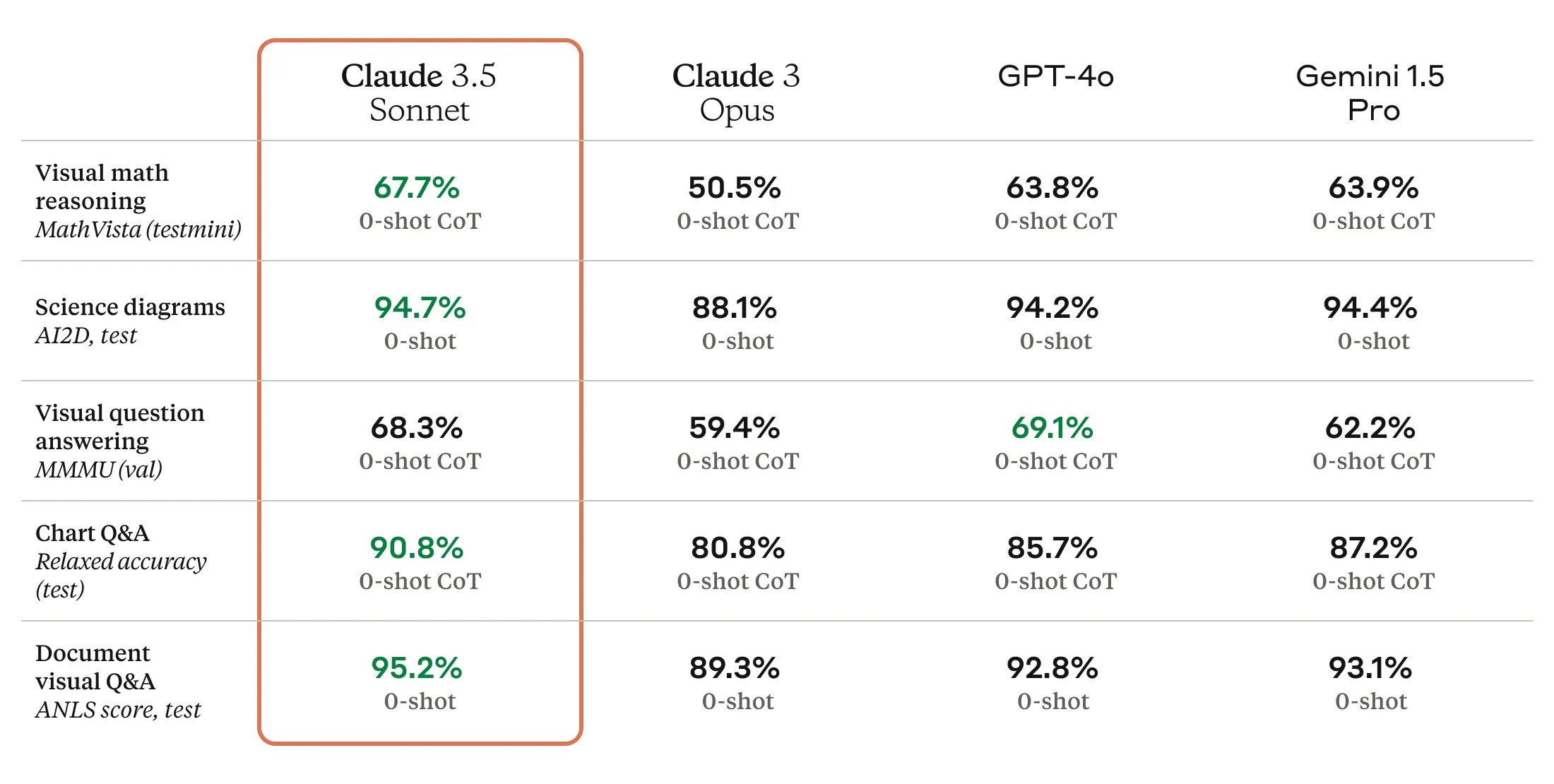
Roughly talking, the visible benchmarks imply that 3.5 Sonnet is best at pulling info from pictures than earlier fashions. For instance, you may present it an image of a rabbit sporting a soccer helmet, and the mannequin is aware of it is a rabbit sporting a soccer helmet and may discuss it. That is enjoyable for tech demos, however the tech remains to be not correct sufficient for purposes of the tech the place reliability is mission essential.
[ad_2]
