

[ad_1]

I’m an Experimental AI Epistemologist. Born in Sweden, now a US Citizen dwelling in Silicon Valley. I’ve an MS in CS with a minor in EE from Hyperlinköping College. Language is my factor. I’m a polyglot (English, Swedish, Finnish, German, and a few French) and have used 30+ pc languages professionally.
I’ve 23 years of expertise of LLM analysis. Not a joke. Fewer than 10 folks could make this declare. I’m possible additionally the world’s foremost knowledgeable on the distinction between twentieth Century and twenty first Century AI; they’re near polar opposites, however most individuals (even within the AI enterprise) haven’t seen this, resulting in cognitive dissonances attributable to attempting to reconcile these gross variations. My outreach focuses on clarifying this. As a touch, Paperclip Maximizers are previous AI and now completely irrelevant.
I invent theories for a way LLMs ought to work, based mostly on far more bioplausible fashions than present LLM designs, after which I check these theories by implementing my very own type of LLMs in Java, C, and Clojure.
This analysis began on Jan 1, 2001, (on prime of a profession in industrial power twentieth Century AI, centered round NLP and Lisp) and has been totally self funded utilizing earnings and inventory choices from Google and some quick time period employments and consulting. A handful of co-researchers working for fairness have helped out over time however the present design is all mine. I personal all of the IP. For now, I exploit commerce secret safety.
I evangelize my Epistemology-level concepts in my AI Meetups, in my Substack, on Fb, and in a dozen movies (extra movies within the pipeline). I’m an achieved public speaker. I ran the Silicon Valley AI Meetup for 100+ meetups over 5 years (2 per 30 days). Most of those featured an hour of my “AI Improv” the place I lead the viewers to find new truths about AI.
Analysis Overview
See an inventory of hyperlinks to printed outcomes at backside of web page.
My LLMs use discrete Pseudo-neurons and pseudo-synapses of a trivial however epistemologically satisfactory design. The variations to present LLMs are hanging; there are numerous, however these ought to reveal the magnitude of the distinction:
In style LLMs vs. Natural Studying
Semantics First vs. Syntax First
Analog idea area vs. Connectome of discrete neurons
Euclidean distance vs. Jaccard Distance
SGD, Backpropagation vs Neural Darwinism
Differentiable vs. Not a requirement
GPUs vs. Not a requirement (gained’t even assist)
Token based mostly enter vs. Character based mostly enter
Embeddings vs. Connectome Algorithms
Parameters vs. Synapse rely
Measurement restricted by GPU RAM vs. Measurement restricted by fundamental reminiscence
Learns in cloudmonths vs. Learns any language syntax in 5 minutes
The algorithm is described in Chapters 8 and 9 (hyperlinks at backside)
Word that the algorithm of my 4 yr previous demo solely handles syntax based mostly (however machine realized, and will have been in any language) classification, not dialog. Past this, I’ve additionally tailored GPT fashion token prediction to my system and I’m implementing that now. No publishable outcomes but. Syntax is sufficient for many twentieth century NLP duties, corresponding to spam/hate/advert filtering and message classification, and my system would nonetheless have a market, if it wasn’t for the runaway success of ChatGPT, which modified the funding panorama.
Alternatively, syntax studying is tremendous low cost and tremendous quick, and may adequately deal with many NLP/NLU duties less expensive than present LLMs, and the power to check a brand new mannequin after a couple of minutes of studying is invaluable to LLM improvement turnaround time.
On a Mac x86 laptop computer, OL learns sufficient English syntax to attain 100% right on my non-adversarial, out-of-corpus, and easy however truthful classification check (see github hyperlink for code and check knowledge).
It learns in below 5 minutes and the UM1, the inference engine, can serve nearly 1 M characters per second for embedding on any cheap machine. Half that velocity on a RPi 4. If you happen to name the UM1 REST service with simply textual content, the outcomes are the pseudo-neuron distinctive identifiers that have been reached in the course of the Understanding of the textual content, as a vector.
Chapter 8 has a brief video of my laptop computer studying English in actual time and repeatedly operating my check. The power necessities to operating GPUs within the cloud has been acknowledged as a significant downside. My techniques might be homeschooled on any laptop computer.
I exploit “Connectome Algorithms” to find abstractions, synonyms, and correlates. These aren’t fairly working but, however indications are that they may nonetheless be less expensive than utilizing GPUs. Though not a good comparability, it’s notable that I estimate my velocity and power benefit of my Syntax Studying over present OL to be a few millionth of the time and power to coach a GPT. The Connectome Algorithms use a bit extra compute. However nonetheless no GPUs, and no cloud required.
My Computing Assets
Under is an image of my analysis setup. Every of the 2 55” screens ($320 FireTVs from Amazon) might be related to 4 completely different computer systems. Two Macs, one Linux field with 2 GPUs (for testing competing LLMS) and one Linux field named “oliver” (named after Oliver Selfridge, the primary AI Epistemologist), with 1.5TB or RAM for my very own algorithms. The quantity of language that “oliver” may study is probably going a lot a lot bigger than what fashionable 80GB GPUs can maintain.
One Mac is exterior my AirGap for internet entry, all others are inside.
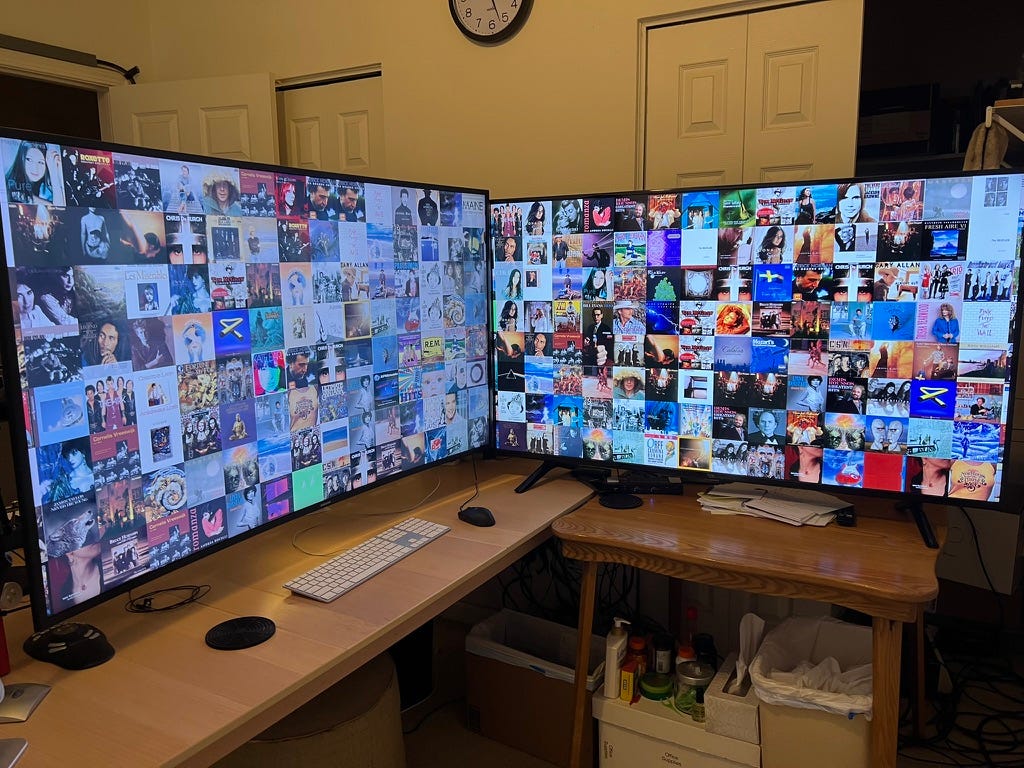
I additionally keep three servers within the cloud.
Funding
I just lately misplaced my fundamental patron (since 5+ years) and am in search of new methods to finance this analysis. I’m open to offering interviews. company workshops about my theories, grants, and co-development offers with firms, and any employment that enables me to maintain all present and future IP to my implementations.
I could take into account VC funding however haven’t pitched anybody since I pitched A16z in 2017, and I really feel that I’m very shut to creating language era work, and subsequently ought to defer pitching till I can reveal it … as a result of the corporate valuation would then be 1000-fold larger.
Hyperlinks
I haven’t been in academia since faculty (I used to be instructing faculty stage AI as an undergrad) and can’t even publish to arXiv with out two printed authors vouching for my competence. So I’ve no tutorial publications.
3 minute silent video on AI Alignment (summarizing the Substack publish):
Analysis house web page: https://experimental-epistemology.ai
Most vital: https://experimental-epistemology.ai/the-red-pill-of-machine-learning/
My LLM: https://experimental-epistemology.ai/organic-learning/
UM1 inference in cloud: https://experimental-epistemology.ai/um1/
I publish most of my materials early (for suggestions) to Fb: https://www.fb.com/pandemonica/https:/
AI Politics Weblog on SubStack: https://zerothprinciples.substack.com
Older movies on vimeo: https://vimeo.com/showcase/5329344
Zeroth Ideas Meetup: https://www.meetup.com/silicon-valley-artificial-Intelligence/
Weblog from 2007: https://www.artificial-intuition.com/
Company web page: https://syntience.com/
My concepts about “anti-social” spam/hate/ad-free social media:
Bubble Metropolis PDF V.2. https://syntience.com/BubbleCity2.pdf
(V.3 can be printed in three components to my SubStack shortly):
Github to check UM1 server: https://github.com/syntience-inc/um1
Some interviews:
https://www.youtube.com/watch?v=Wj2TQor5QPY
https://www.youtube.com/watch?v=Y82sMnvPYKU
https://www.youtube.com/watch?v=2ehIRRyNNTo
My robotic: https://www.youtube.com/watch?v=REzrYWOzhWc
Bonus: My profile image is from a gaggle dinner with pals in June 2024. Do you acknowledge the gentleman sitting subsequent to me, a pal since 20 years? If you don’t, google his T-shirt which says “Potrzebie!” He likes his privateness and I not often share this.

[ad_2]
